Inside Claude Code
Issue #62 | 从 500,000 行生产级 Agent 代码中学到的构建和优化 Agent 的经验
最近(2026 年 3 月 31 日),Claude Code 的完整 TypeScript 源码随 @anthropic-ai/claude-code npm 包意外发布。这让我们得以一窥 Anthropic 如何构建这个被数十万开发者使用的生产级 Agent harness。我花了时间阅读代码、运行分析脚本,并深入挖掘了 Claude Code 团队的设计决策。本文整理了这些发现。
TLDR;
本文中所有 insight 均来自代码阅读和工程师在代码中的注释。作为背景,本文建立在之前关于 Agent 执行循环和从头构建自己的 Claude Code 的文章之上。
By the Numbers
在深入经验之前,先看一下代码库的全貌。我写了一个 Python 脚本遍历完整源码树并生成这些图表。数据来自 2026 年 3 月 31 日的 npm 包。
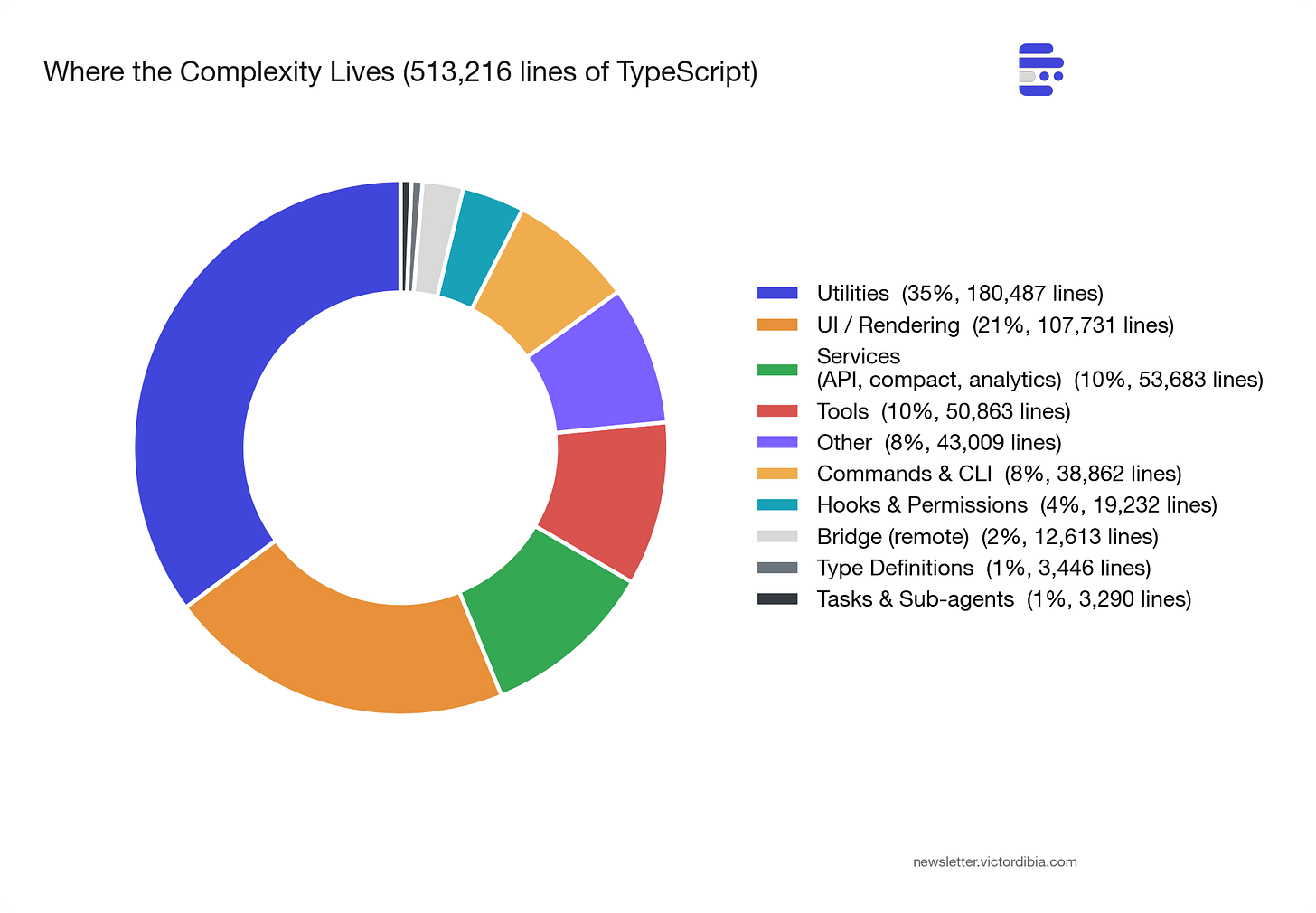
513,216 行 TypeScript,分布在 1,884 个文件中。42 个工具。90 个功能开关。
The agent loop is less than 1% of the codebase. The other 99% keeps it alive …
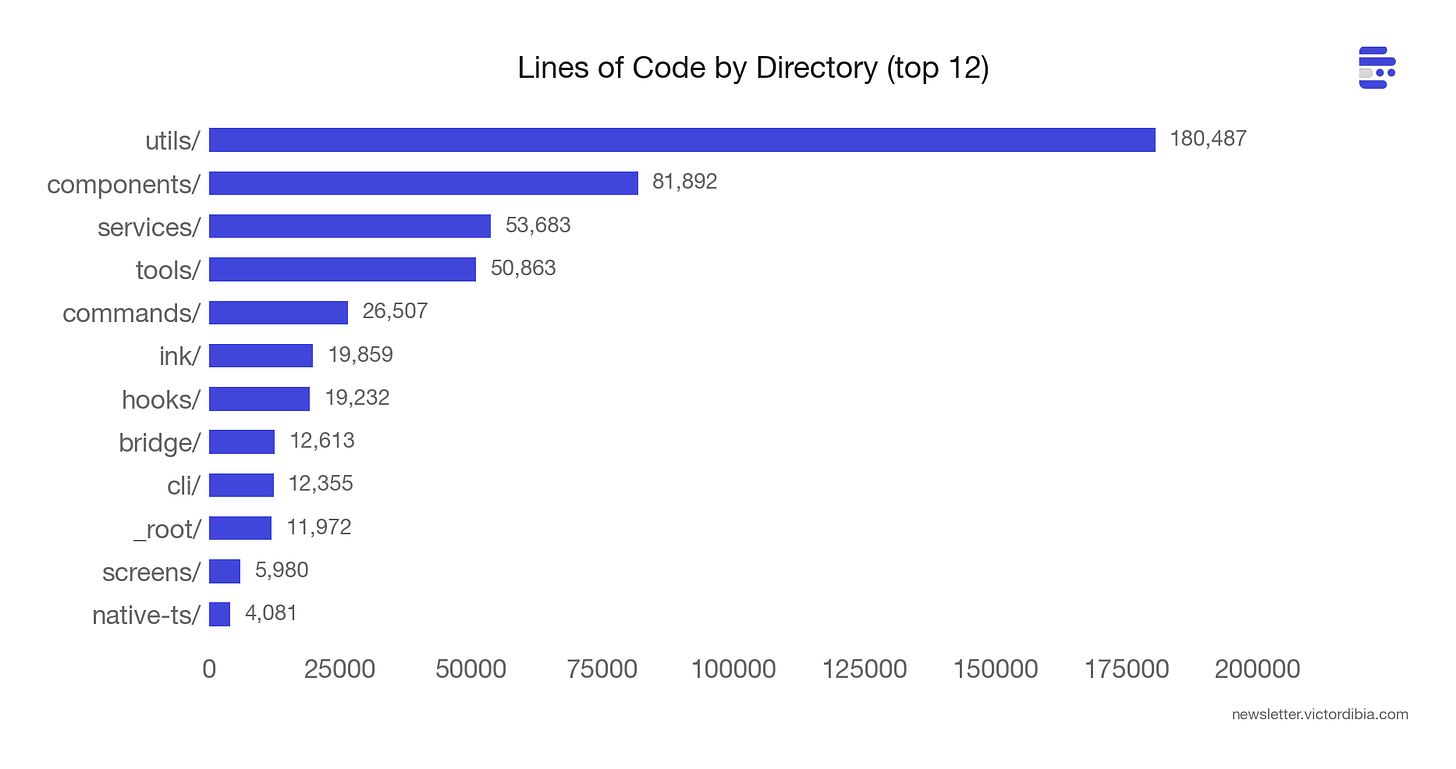
最大的意外:utils/ 目录以约 180,000 行(占代码库 35%)成为最大目录。支撑 Agent 的基础设施——模型路由、权限管理、配置加载、分析、错误处理——远超 Agent 本身。
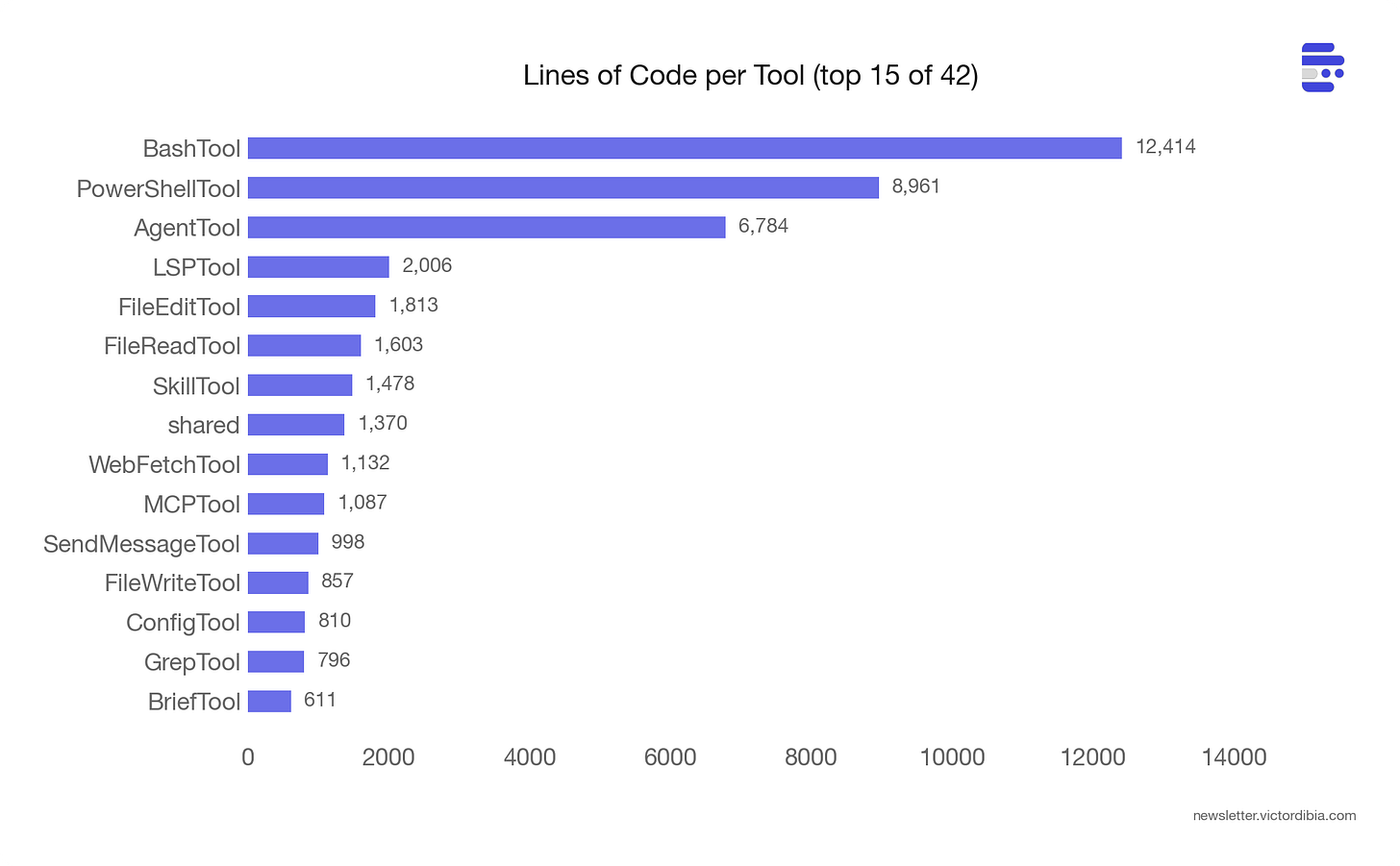
BashTool: 1,143 lines of execution, 11,271 lines of making sure the execution is safe.
BashTool 共 12,414 行——其中工具本身(BashTool.tsx)只有 1,143 行。剩余约 11,000 行是安全基础设施:
- AST 解析
- 危险命令检测
- 超时处理
- 输出截断
- Shell 拼写检查
工具是 10% 执行逻辑,90%”确保执行安全”。
PowerShellTool 有 8,961 行——从零重新实现(非 BashTool 移植),包含 PowerShell 特定威胁:download cradles(Invoke-WebRequest | Invoke-Expression)、COM 对象滥用、Constrained Language Mode 绕过检测、通过变量的动态命令名、模块加载攻击。Windows shell 安全是一个与 Unix 不同的威胁模型,代码似乎在工程层面反映了这一点。
AgentTool(管理子 Agent 生成)有 6,784 行。较小的工具(Glob、Grep、Sleep)各 50-300 行。复杂度集中在攻击面最大的地方。
Lesson 1: 大部分代码不是 Agent 循环
Claude Code 的核心循环在 query.ts 中是可识别的。它是一个 while (true) 循环,调用 Claude API、从响应中收集 tool_use 块、执行它们、将 tool_result 消息推回,然后循环。这与之前文章描述的 Agent 循环镜像。
但这个循环携带一个包含 10 个字段的 State 对象:
const state = {
messages: [], // 消息历史
toolUseContext: {}, // 工具调用上下文
autoCompactTracking: undefined, // 自动压缩追踪
maxOutputTokensRecoveryCount: 0, // 最大输出 token 恢复计数
hasAttemptedReactiveCompact: false, // 是否尝试过响应式压缩
maxOutputTokensOverride: undefined, // 最大输出 token 覆盖
pendingToolUseSummary: undefined, // 待处理工具摘要
stopHookActive: undefined, // 停止钩子是否激活
turnCount: 0, // 轮次计数
transition: undefined, // 循环继续的原因
};很多细节在其中。transition 字段记录了循环在上一次迭代中为何继续:是正常的工具执行轮次?prompt 太长错误后的恢复?还是最大输出 token 升级?每个继续都有一个名称,使调试和遥测变得直接。
这个循环有五条不同的恢复路径来处理 API 错误:
// 伪代码 - 展示恢复链
async function runLoop(state) {
while (true) {
try {
const result = await callClaudeAPI(state);
// 正常完成
return result;
} catch (error) {
if (error.type === 'prompt_too_long') {
// 路径1: 触发压缩
await compactContext(state);
continue;
}
if (error.type === 'rate_limit') {
// 路径2: 指数退避重试
await exponentialBackoff(state);
continue;
}
if (error.type === 'max_output_tokens') {
// 路径3: 升级到更大 token 限制
state.maxOutputTokensOverride = 64000;
continue;
}
if (error.type === 'connection_error') {
// 路径4: 尝试 HTTP polling 回退
await pollForResult(state);
continue;
}
if (error.type === 'unknown') {
// 路径5: 最后一次尝试
await lastResortRetry(state);
continue;
}
// 所有恢复选项用尽,放弃
throw error;
}
}
}每个已知错误类都有自动化恢复路径。prompt_too_long 触发压缩。最大输出 token 触发从 8k 到 64k 的升级。用户看不到这些——循环静默吸收失败,只在所有恢复选项用尽后才暴露错误。
180,000 lines of utilities. The infrastructure you never see outweighs the features you do
那个循环约 1,700 行。其余 511,000 行是它能可靠运行 50+ 轮的原因。工具编排、权限管理、上下文预算、分析、错误分类、会话内存、模型路由、配置加载。循环是 Agent 运行的地方。其他一切是 Agent 存活的地方。
在大多数实现中,循环很快稳定。Harness——工具安全、上下文管理、错误恢复、权限(所有都是为了捕获出现的边缘情况)——才是工程努力随时间累积的地方。
Lesson 2: Prompt 是你看不见的最大工程投入
我预期系统 prompt 会很大。在《Designing Multi-Agent Systems》第 11 章中,我把糟糕的指令列为多 Agent 系统失败的 10 个原因之一。但代码库中约 60,000 token 的 prompt 文本比大多数工程团队预期的要大。
60,000 tokens of prompt text. Every token is a failure mode someone hit in production.
系统 prompt 本身约 19,000 token,由约 15 个可组合的 section 函数构建(getSimpleIntroSection、getUsingYourToolsSection、getSimpleDoingTasksSection 等),带有 SYSTEM_PROMPT_DYNAMIC_BOUNDARY 标记将可缓存内容与会话特定内容分开。存在这个边界是因为 Anthropic 的 prompt 缓存对缓存命中收取更少费用——所以边界前的所有内容在各轮之间保持稳定,之后(会话特定指导、MCP 指令)可以自由更改。
工具 prompts 才是主要投入所在。
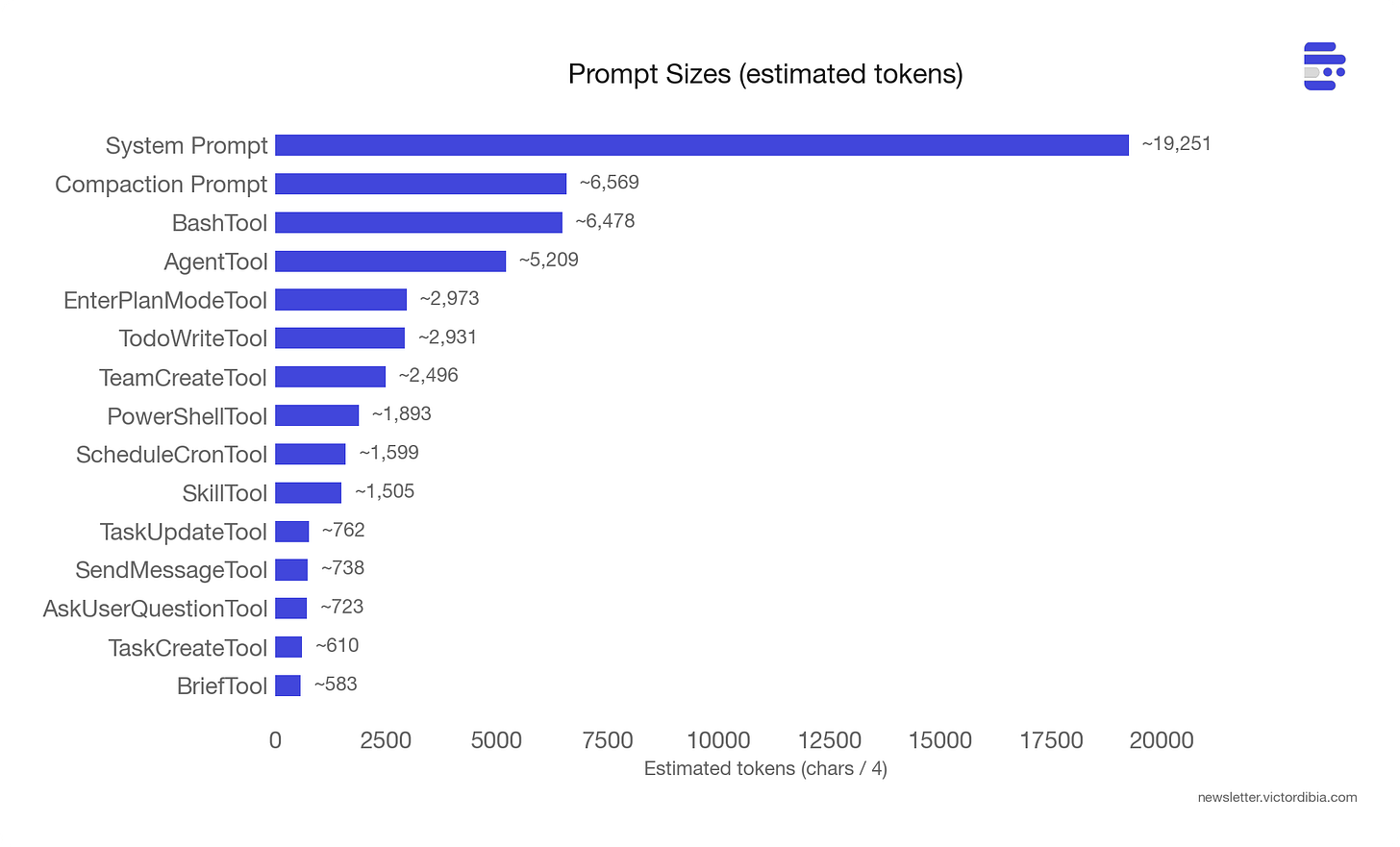
The system prompt isn’t one prompt. It’s 15 composable functions split by a cache boundary.
BashTool prompt 约 6,500 token。它包含一个完整的反模式目录:不要对大文件使用 cat(用 head/tail)、不要对你未修改的代码添加文档、不要在 git hook 失败后 amend commit(因为 hook 已经成功,--amend 会修改上一个 commit)、不要使用 -i 标志(交互模式在非交互 shell 中不工作)。每一条都是一个在生产规模上发生的具体失败模式,被检测到后被编码到 prompt 中。
系统 prompt 的 getSimpleDoingTasksSection 同样有主见——而且这些主见可能来自观察模型在实践中的失败。直接引用源码:
一次只做一件事。当任务完成时停止。
如果用户提供了文件路径,直接使用它,不要假设。
遇到错误时,修复错误而不是绕过它。
prompt 用 @[MODEL LAUNCH] 标记(26 个文件中共 49 处)标注了需要在新模型版本发布时审查的部分。一个标记写道:”Capybara v8 的虚假声明缓解(29-30% FC 率 vs v4 的 16.7%)。”某些规则只适用于特定模型。随着模型改进,某些规则会被放宽。Prompt 随着模型演变。
压缩 prompt(约 6,500 token)展示了模型特定 prompt 调优的实践。当 Claude Code 压缩对话时,它生成一个分叉子 Agent,其唯一工作是生成文本摘要。该分叉继承父级的完整工具集——不是因为它需要工具,而是因为 Anthropic 的 prompt 缓存按工具定义匹配。不同工具意味着缓存未命中,这意味着从头重新处理整个系统 prompt。所以分叉保留工具以获得缓存命中。
这个工具包含的副作用是模型看到 42 个可用工具,有时可能尝试使用它们而不是写摘要。在 Sonnet 4.5 上,这发生率为 0.01%。在 Sonnet 4.6 上,跳升至 2.79%(per prompt.ts 中的注释)。由于分叉以 maxTurns: 1 运行,工具调用意味着没有摘要输出——压缩静默失败。修复是一个直白的开场白:
const preamble = `
CRITICAL: Respond with TEXT ONLY. Do NOT call any tools.
Tool calls will be REJECTED and will waste your only turn - you will fail the task.
`.trim();这个 prompt 存在是因为一个特定模型版本上的特定回归,通过遥测捕获,通过引导语言修复。大规模 prompt 工程是响应式的——你从生产数据中发现失败模式,而不是从第一性原理。
Lesson 3: 上下文管理是一个管道,而非单一操作
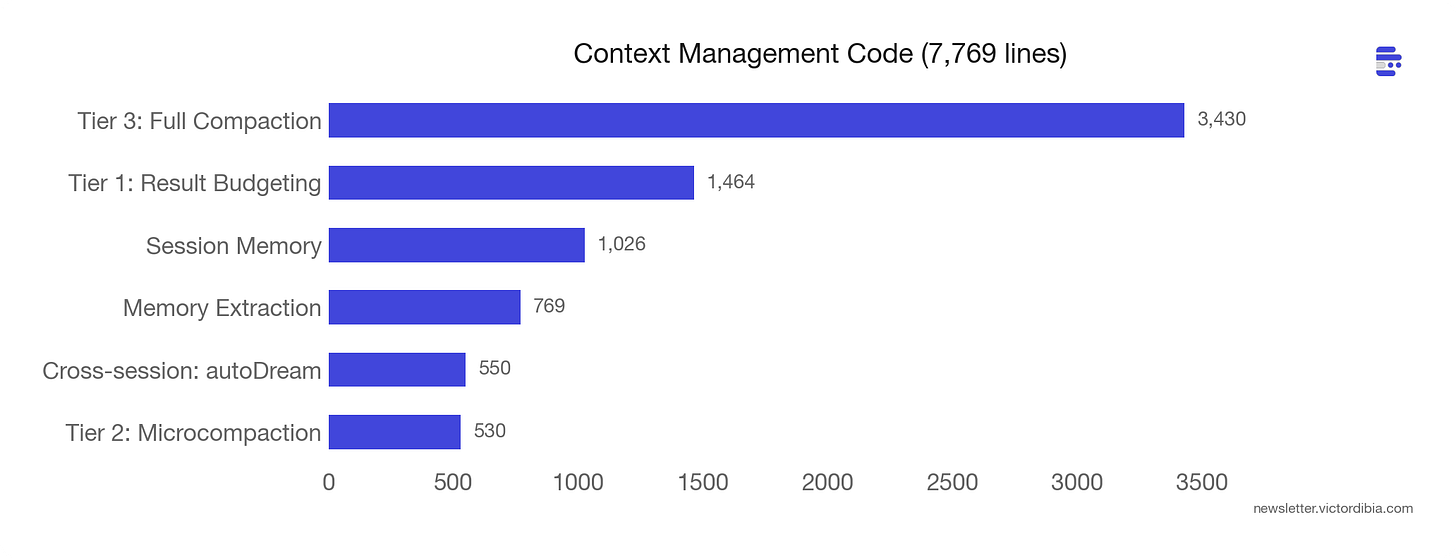
在上一篇文章中,我把压缩作为单一操作——当上下文变得太大时,总结/裁剪/减少它。Claude Code 有三个层级组成管道。在每次 API 调用前,循环按顺序经过它们:预算 → 微压缩 → 完全压缩。

Context management isn’t one operation. It’s six subsystems across 7,769 lines.
第一层:工具结果预算(按结果)
在结果进入对话之前,大输出被持久化到磁盘并替换为 2KB 预览加文件路径。模型可以按需使用 Read 工具获取完整输出。这是上下文的按需分页——将摘要保留在工作内存中,将完整数据放在磁盘上(类似于 skills 中使用的渐进披露模式)。
每个工具声明一个 maxResultSizeChars 阈值(默认 50k 字符)。Read 工具完全退出(阈值设为 Infinity),因为将其输出持久化到模型用 Read 读回的文件是循环的。
第二层:微压缩(选择性清除)
清除特定工具类型的结果:Read、Bash、Grep、Glob、WebFetch、Edit、Write。使用基于时间的触发器:如果自上一条助手消息以来的时间间隔超过阈值,服务器端 prompt 缓存已经过期。所以在请求之前清除陈旧的工具结果——没有理由重新缓存服务器已经忘记的内容。
第三层:完全压缩(LLM 摘要)
当上下文超过 contextWindow - reservedForSummary - 13,000 token 缓冲区时触发。使用 Claude 本身将对话总结为九个结构化 section:
const compactionSchema = {
userRequest: "", // 用户原始请求(逐字)
currentProgress: "", // 当前进度
filesReviewed: [], // 已审查文件
filesModified: [], // 已修改文件
commandsExecuted: [], // 已执行命令
keyDecisions: [], // 关键决策
blockers: "", // 当前障碍
nextSteps: "", // 下一步计划
verbatimQuotes: [], // 逐字引用(防止意图漂移)
};最后一个要求——逐字引用——防止最常见的压缩失败:意图漂移。总结后,Agent 可能微妙地重新解读用户的要求。要求精确引用将摘要锚定在用户实际说出的词语上。
总结后,Claude Code 重新注入最后 5 个文件附件(各最多 5K token)、活动 skills(最多 25K 总计)、计划状态和工具/MCP delta 附件。这里的压缩是结构化提取后跟选择性重建,schema 围绕 SWE 任务调整——文件路径、代码片段、错误历史。对于其他领域(法律、医疗),压缩 schema 可能看起来非常不同。
单次迭代可能预算一个大 Bash 结果(第一层),因为缓存过期而清除旧的 Grep 结果(第二层),并且仍然需要完全压缩,因为对话已经运行了 40 轮(第三层)。每个层级处理不同形状的上下文增长。
除这三个层级外,还有跨会话记忆。一个标记的 autoDream 子系统在会话之间运行后台记忆整合,使用三门系统(最便宜检查优先):自上次整合以来的时间 → 自上次整合以来的会话计数 → 锁检查。它触发一个 /dream prompt 作为分叉子 Agent 来提取跨会话的模式。每个时间尺度上的上下文管理。
Lesson 4: 每条恢复路径需要一个断路器
代码有引用内部 bug 查询(BQ)的注释,带有具体日期和编号。有三个特别突出:
BQ 2026-03-10: “1,279 个会话在单个会话中有 50+ 次连续压缩失败(最多 3,272 次),每天浪费约 250K API 调用。”
修复:MAX_CONSECUTIVE_AUTOCOMPACT_FAILURES = 3。三行代码。问题未被注意到,因为自动压缩失败是静默的——重试逻辑只是一轮又一轮地继续。没有遥测,这看起来像正常的 API 流量。
BQ 2026-03-12: “~98% 的 ws_closed 事件通过 polling alone 无法恢复。”
当 Claude Code 的 WebSocket 桥接断开时,它回退到 HTTP polling。但数据显示 98% 的断开会话通过 polling 从未恢复。每周 147,000 个会话遇到 poll 404。修复是一个完整的重连状态机,包含两种策略:原地重连(相同环境 ID)或全新会话回退。
BQ 2026-03-01: “缺失 [缓存失效] 导致 20% 的 tengu_prompt_cache_break 事件。”
一个微妙的。微压缩更改系统 prompt,这应该使 prompt 缓存失效。缺失这个失效意味着 20% 的 prompt 缓存中断是由系统自身的上下文管理引起的,而非实际内容更改。修复是在微压缩后添加单个标志检查。
代码库中有 20 个断路器常量:
const CIRCUIT_BREAKERS = {
MAX_CONSECUTIVE_AUTOCOMPACT_FAILURES: 3,
MAX_POLLING_RETRIES: 5,
MAX_RATE_LIMIT_RETRIES: 7,
MAX_CONNECTION_ERROR_RETRIES: 3,
MAX_OUTPUT_TOKEN_ESCALATIONS: 2,
MAX_COMPACTION_ATTEMPTS: 5,
POLLING_TIMEOUT_MS: 30000,
RECONNECT_MAX_ATTEMPTS: 10,
// ... 等
};代码库中每条自动化恢复路径都有相应的断路器限制重试次数。 数字很小(1-10),注释解释原因,BQ 引用显示弄错它的代价。没有最大值,恢复本身成为问题。
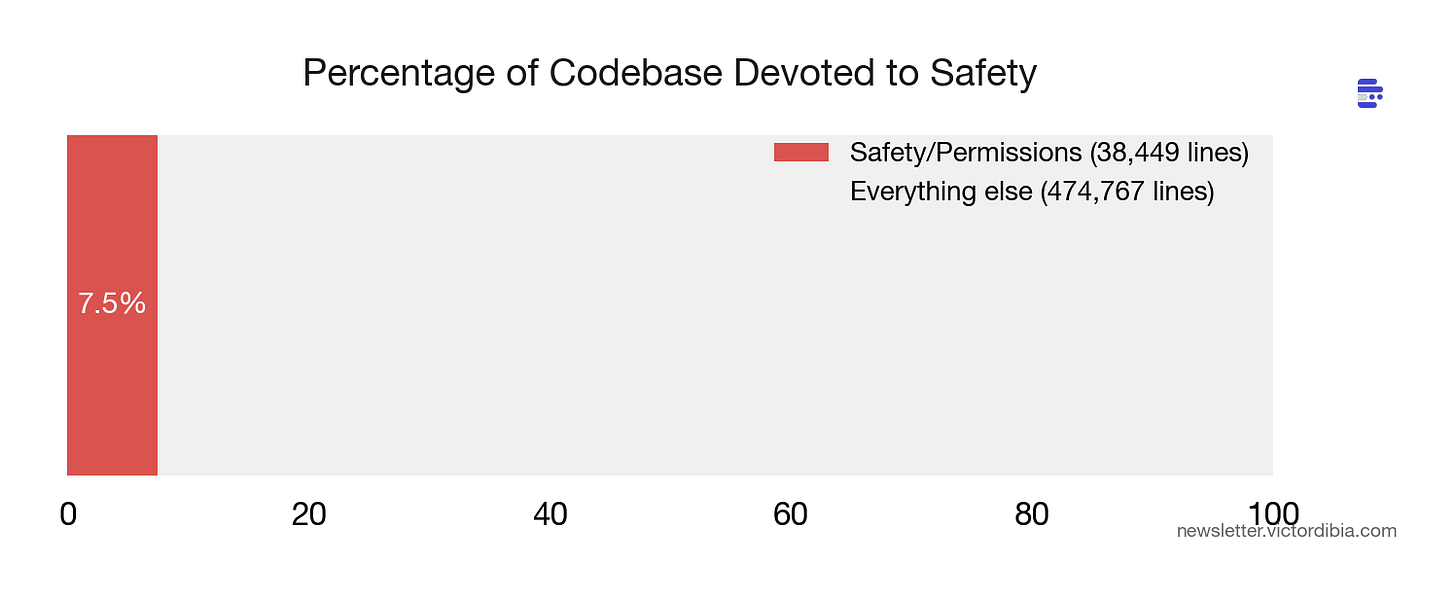
Lesson 5: 安全比功能扩展更快
7.5% of the codebase does nothing but say no (or dictates when to say no)
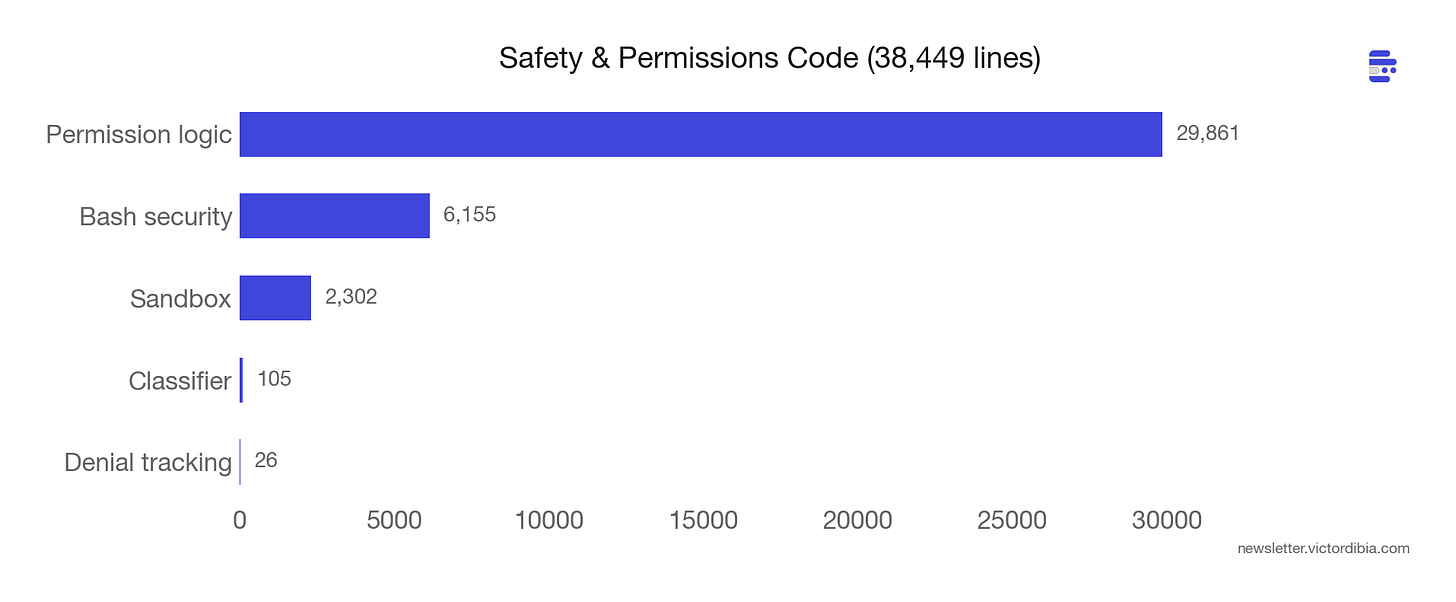
38,449 行。占整个代码库的 7.5%。专门用于权限和安全。
Permission logic alone is 30,000 lines. Bash security is another 6,155.
BashTool 单独有 20+ 安全检查,使用 tree-sitter AST 分析(而非正则)。这些检测:
- 危险命令(
rm -rf、fork bomb) - 路径遍历
- 环境变量注入
- Shell 变量展开
- 重定向和管道
- 后台进程
- 超时命令
- 网络相关命令
单独地,destructiveCommandWarning.ts 匹配 git reset --hard、rm -rf、DROP TABLE、kubectl delete 等模式。这些警告但不阻止——区别很重要。破坏性命令不一定错误,只是需要明确确认。
Bash 命令的完整权限流程经过四层:
- 配置规则 → 处理快速路径
- Hooks → 处理组织特定策略
- 分类器 → 捕获边缘情况
- 用户对话框 → 最后手段
每层可以短路。系统设计使大多数工具调用在第一层解决(快速、无用户交互),只有真正模糊的才到达第四层。
子 Agent 添加另一个维度:权限边界。子 Agent 不能显示 UI 对话框,因此任何未决定的权限提示都会被自动拒绝。Hooks 可以预先批准特定操作——这就是子 Agent 无需人工交互即可运行 npm test 的方式。Abort 控制器链接父到子(父中止级联下,子失败不杀死父)。任务注册总是到达根存储,这样子 Agent 生成的后台 bash 进程不会变成僵尸进程。
系统 prompt 本身将安全编码为行为指导。getActionsSection 函数生成如下规则(引用源码):
measure twice, cut once
永不跳过 hooks(--no-verify)
永不 force-push 到 main
在删除之前调查不熟悉的文件(它们可能是用户进行中的工作)
这些读起来像压缩成一句话的事后验尸。
cron 调度器(用于计划的远程 Agent 运行)有一个有趣的细节:它故意避免在整点和半点调度,以防止数千个 Agent 同时触发时造成全集群 API 峰值。
安全代码随能力超线性增长。每个新工具需要权限逻辑。每个新模型需要 prompt 调优。每个新部署模式(远程、子 Agent、无头)需要自己的权限边界。这是 Agent 开发中不会变得更容易的部分。
Lesson 6: 单 Agent 正在变成团队
代码库包含 90 个功能开关,隐藏在 Bun 的构建时死代码消除后面。大多数未向外部用户发布。但它们揭示了轨迹。
90 feature flags. Most of them are for features you’ve never seen
六个开关明确是多 Agent 的:
const MULTI_AGENT_FLAGS = {
MULTI_AGENT_COLLABORATION: false, // 多 Agent 协作
AGENT_TEAM_ORCHESTRATION: false, // Agent 团队编排
CROSS_AGENT_MEMORY: false, // 跨 Agent 记忆
AGENT_HIERARCHY: false, // Agent 层级
DISTRIBUTED_AGENTS: false, // 分布式 Agent
AGENT_COMMUNICATION: false, // Agent 通信
};助手模式子系统(内部代号 KAIROS)添加了六个更多开关:后台记忆整合(KAIROS_DREAM)、主动简报(KAIROS_BRIEF)、GitHub webhook 订阅(KAIROS_GITHUB_WEBHOOKS)、推送通知(KAIROS_PUSH_NOTIFICATION)、渠道集成(KAIROS_CHANNELS)。
autoDream 系统特别有趣。它在会话之间作为分叉子 Agent 运行 /dream prompt 来整合记忆。它使用三门系统,按最便宜优先排序:时间门(自上次整合以来小时数)→ 会话门(有足够新会话证明合理性)→ 锁门(没有其他进程正在整合)。
然后是 buddy 系统:18 个 ASCII-art 伙伴物种,带有 gacha 稀有度等级(common 到 legendary)、RPG 属性(DEBUGGING、PATIENCE、CHAOS、WISDOM、SNARK),以及每个伙伴的模型生成”灵魂”。这是当工程师热爱他们的产品时会发生的事。
第 1-5 课中的模式——恢复路径、分层上下文管理、权限边界、断路器——是这些多 Agent 系统的构建块。
除多 Agent 开关外,代码库包含在 feature() 检查后面、未在外部构建中发布的功能的完整实现。几个值得注意的:
语音模式(VOICE_MODE)——使用 claude.ai 的 voice_stream 端点的语音输入/输出。创建 /voice 命令。通过服务器端 GrowthBook 标志终止。
原生 Web 浏览器(WEB_BROWSER_TOOL,代号”bagel”)——使用 Bun 原生 WebView 的浏览器工具。在页脚药丸中显示活动页面 URL,带有粘性面板。终端 Agent 内部的完整浏览器。
远程规划(ULRAPLAN)——将规划阶段传送到云浏览器会话。有完整状态机:running → needs_input → plan_ready → approved/rejected。用户在一个浏览器 UI 中审查和批准计划,然后 Agent 执行。
深度链接协议(DIRECT_CONNECT)——带有 HTTP 会话服务器、auth tokens、unix sockets、空闲超时和最大会话限制的 cc:// URL 协议。创建 claude server、claude connect <url>、claude open <cc-url> 命令。
自托管运行器(SELF_HOSTED_RUNNER)——用于 bring-your-own-compute 部署的注册和轮询工作程序服务。与 BYOC_ENVIRONMENT_RUNNER 配对用于无头执行。
反蒸馏(ANTI_DISTILLATION_CC)——在 API 调用中发送虚假工具定义,以防止其他公司通过观察 Claude Code 的 API 流量提炼模型行为。
贴纸(STICKERS)——在浏览器中打开 stickermule.com/claudecode。注册为斜杠命令。代码库中最积极向上的功能开关。
除六课外,代码库充满了展示来之不易的工程知识细节。以下是一些突出的:
流式工具执行。 Claude Code 不等待模型完成生成就开始工具执行。StreamingToolExecutor 在流中每个 tool_use 块完成时开始运行工具。如果模型请求三个文件读取,第一个在第二和第三个仍在生成时开始执行。一个微妙之处:当 Bash 命令出错时,它中止同一批次中的所有兄弟工具(因为 shell 命令通常有隐含的依赖链——如果 mkdir 失败,后续命令毫无意义)。但 Read 和 WebFetch 错误不会级联——那些工具是独立的。
通过类型系统的隐私。 分析系统使用一个名为 AnalyticsMetadata_I_VERIFIED_THIS_IS_NOT_CODE_OR_FILEPATHS 的类型。向分析传递字符串的每个开发者必须将其强制转换为这个类型,迫使他们有意识地验证他们没有意外记录用户代码或文件路径。荒谬的长名称就是重点——这是对社会工程防御隐私泄露的内置于编译器的防御。
构建时字符串排除。 一个名为 excluded-strings.txt 的文件列出了绝不能出现在外部构建中的字符串——模型代号、内部 API 前缀、组织标识符。捆绑后,一个脚本 grep 输出寻找这些字符串。如果任何字符串存活,构建失败。要解决这个问题,代码库在运行时构造敏感字符串:['sk', 'ant', 'api'].join('-') 而不是 'sk-ant-api'(压缩器无法常量折叠 join())。Buddy 物种名称使用 String.fromCharCode(0x63,0x61,0x70,0x79,0x62,0x61,0x72,0x61),因为”capybara”与排除列表中的模型代号冲突。
undercover 模式。 当 Claude Code 为公共仓库做贡献时,一个”undercover”系统防止它暴露它是 AI。Commit 消息、PR 标题和 PR 正文被清除 Anthropic 内部信息。系统没有强制关闭开关——源码注释写道:”如果我们不确定我们在内部仓库,我们保持 undercover。”
空工具结果会打断模型。 一个 bug(源码中的 inc-4586)揭示,在 prompt 末尾的空的 tool_result 内容会导致某些模型发出 \n\nHuman: 停止序列,以零输出结束他们的轮次。模型有效地将空结果解释为对话边界。修复:注入 (tool_name completed with no output),这样结果永远不为空。
缓存稳定性是神圣的。 内容替换系统(将大工具结果持久化到磁盘)永久冻结每个决定。一旦结果被替换为预览,那个精确的预览字符串被存储并在每轮后续中重新应用。一旦结果保留在上下文中,它永远不会被替换。任何更改都会移动 prompt 前缀并破坏 prompt 缓存。替换字符串被逐字存储而不是重新生成——所以即使预览模板的代码更改也不会静默破坏缓存命中。
顾问模式。 一个标记的”advisor”系统让工作模型在任务中途咨询一个更强的审查模型。Prompt 指令(来自源码)是具体的:”在实质性工作之前调用顾问——在写代码之前,在承诺一个解释之前。”还有:”在这个调用之前,让你的交付物持久化:写文件,stage 更改。顾问调用需要时间;如果会话在此期间结束,持久化的结果存在,未写下的不存在。”
auto-mode 分类器叫做 yoloClassifier。 文件名、变量名和内部引用都使用”YOLO”作为自动批准工具调用的术语。有时候命名告诉你团队如何看待一个功能。
结论
在涉过 500,000 行源码之后(期间 Claude 作为助手),最引人注目的是有多少映射到之前关于 Agent 执行循环和从头构建自己的 Claude Code 的文章。核心循环是一个带有工具执行的 while 循环。工具是有 schema 的函数。Hooks 在循环边界拦截。压缩管理上下文增长。子 Agent 提供隔离。架构不变。失败模式成倍增加。
当然,不是这里的一切都适用于你的 Agent。 Claude Code 是一个服务于数十万并发用户的终端 harness,构建在 Anthropic 的 prompt 缓存计费模式上。缓存对齐的压缩边界、全集群 cron 抖动、流式工具执行——这些是对特定规模和接口的响应。如果你正在构建一个医疗 intake agent 或法律文档审查器,你的压缩 schema 需要不同的 section(患者历史,而不是文件路径),你的安全深度不同(只读数据库查询比 shell 执行需要更少的防护),大多数缓存优化是多余的。
普遍适用的模式:
- 循环是 10% 执行,90% 是保持它运行的东西
- 恢复路径需要断路器
- 提示工程是反应式的——从生产数据中发现失败模式
- 上下文管理是一个管道,而非单一操作
- 安全比功能扩展更快
原文链接:Inside Claude Code
翻译 — Mar 31, 2025

Made with ❤ and at Guangzhou.
