Agent Middleware:为 AI Agent 添加控制与可观测性

Issue #53 | 如何在 agent 操作中植入日志、安全检查、限流和合规能力——生产级 AI agent 的中间件模式。
前言
在之前关于 agent 执行循环的文章中,我展示了 agent 的工作原理:一个 while 循环,反复调用 model、执行 tool,直到完成。这个循环是引擎,也就是 harness。
但引擎需要控制程序来治理行为。
当你要把 agent 部署到生产环境时,新问题随之出现:
- 如何记录每一次 model 调用和 tool 执行?
- 如何在恶意 prompt 进入 LLM 之前将其拦截?
- 如何对用户进行限流以控制成本?
- 如何在输出到达用户或遥测系统之前去除 PII?
- 如何生成合规审计日志?
一种解决方案是 middleware —— 在执行循环的关键节点(如 model 调用前后、tool 调用前后)拦截 agent 操作的例程。如果你用过 Express、Django 或 FastAPI 开发 Web 应用对这个模式应该不陌生。它用在 agent 上同样有效。
注:本文改编自我的新书 Designing Multi-Agent Systems,第 4 章会带你从头构建一个完整的 Agent 类。该 agent 类是 PicoAgents 的一部分——一个极简、可定制的多 agent 框架。书中各章节读者会逐步构建整个框架。本文示例虽基于 picoagents,但同样适用于 LangChain、Microsoft Agent Framework 等其他框架。
什么是 Agent Middleware?
Middleware 在 agent 操作执行之前和之后对其进行拦截。当 agent 准备调用 LLM 或执行某个 tool 时,该操作会首先经过一条 middleware 链。每个 middleware 可以:
- 修改请求或响应
- 记录操作日志
- 允许操作通过或阻止其执行
核心心智模型:
请求 → [Middleware 1] → [Middleware 2] → [执行操作] → [Middleware 2'] → [Middleware 1'] → 响应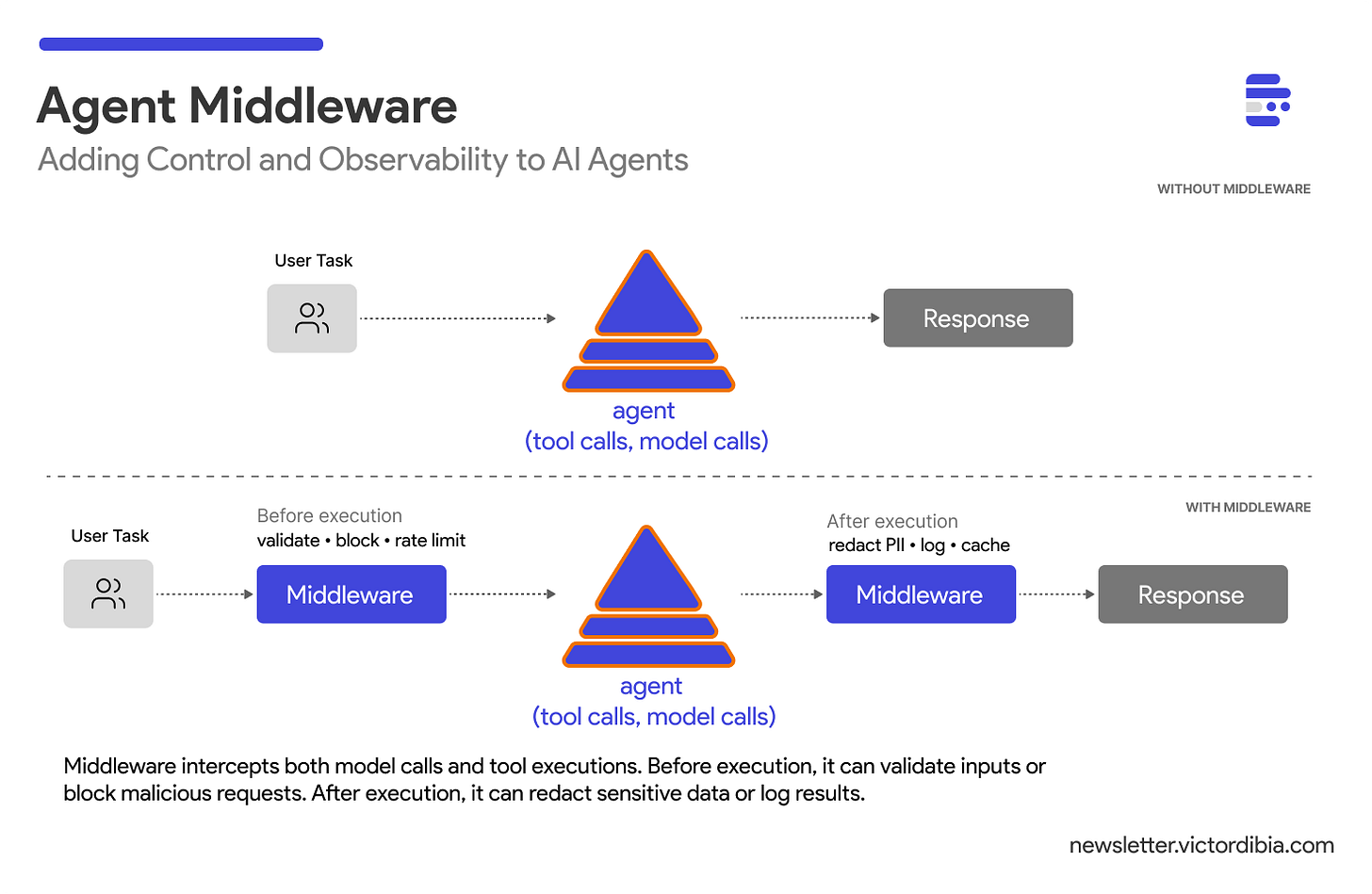
所有 model 调用和 tool 执行都经过这条 middleware 链。这给了你一个统一的安全、可观测性和策略执行的控制平面。
BaseMiddleware 接口
为了统一 middleware 的行为,我们定义了一个包含三个钩子的通用接口。使用 async generators(async + yield)而非返回值——这样可以支持流式响应和可观测性事件:
// 抽象基类 - 所有 middleware 继承此类
class BaseMiddleware {
constructor() {
if (this.constructor === BaseMiddleware) {
throw new Error('BaseMiddleware is abstract and cannot be instantiated directly');
}
}
// 操作执行前运行
// 可在此验证输入、启动计时器或阻止可疑请求
// 返回 context 继续执行,抛出异常中止操作
async *processRequest(context) {
yield context;
}
// 操作成功完成后运行
// 可在此过滤输出、缓存结果或记录完成时间
// 返回(可能被修改后的)结果
async *processResponse(context, result) {
yield result;
}
// 处理操作失败
// 可在此记录错误、提供降级方案或实现重试逻辑
// 返回一个恢复值,或 re-throw 向上传播错误
async *processError(context, error) {
throw error;
}
}使用 async generator 模式(yield 而非 return)使 middleware 能够发射可观测性事件,并支持流式响应——这两点对生产级 agent 都至关重要。
示例一:Logging Middleware
最简单、也最有用的 middleware——记录所有操作。
const { BaseMiddleware } = require('./middleware');
class LoggingMiddleware extends BaseMiddleware {
constructor() {
super();
}
async *processRequest(context) {
const startTime = Date.now();
console.log(`[${context.agentName}] 开始执行 ${context.operation}`);
context.metadata = { ...context.metadata, startTime };
yield context;
}
async *processResponse(context, result) {
const duration = ((Date.now() - (context.metadata?.startTime || 0)) / 1000).toFixed(2);
console.log(`[${context.agentName}] ${context.operation} 完成,耗时 ${duration}s`);
yield result;
}
async *processError(context, error) {
console.log(`[${context.agentName}] ${context.operation} 失败: ${error.message}`);
throw error;
}
}使用方式:
const agent = new Agent({ middleware: [new LoggingMiddleware()] });输出示例:
[MyAgent] 开始执行 model_call
[MyAgent] model_call 完成,耗时 1.23s
[MyAgent] 开始执行 tool_call (search)
[MyAgent] tool_call (search) 完成,耗时 0.45s所有操作现在都一目了然。调试 agent 为何做出某个决策,或测量延迟时,这是你的第一道防线。
示例二:Guardrail Middleware
Agent 易受 prompt injection 攻击——恶意输入劫持模型行为。Guardrail middleware 可以在危险模式进入 LLM 之前将其拦截:
const { BaseMiddleware } = require('./middleware');
class GuardrailMiddleware extends BaseMiddleware {
constructor(blockedPatterns = null) {
super();
// 演示用基础模式
this.blockedPatterns = (blockedPatterns || [
/ignore.*previous.*instructions/i,
/system.*prompt.*override/i,
/<script.*?>.*?<\/script>/i,
]).map(p => new RegExp(p));
}
async *processRequest(context) {
if (context.operation === 'model_call') {
const messages = context.data;
for (const message of messages) {
if (message.content) {
for (const pattern of this.blockedPatterns) {
if (pattern.test(message.content)) {
throw new Error(`已阻止危险模式: ${pattern}`);
}
}
}
}
}
yield context;
}
async *processResponse(context, result) {
yield result;
}
async *processError(context, error) {
throw error;
}
}当 middleware 检测到危险模式时,会立即抛出异常。恶意输入永远不会到达模型——不会产生昂贵的 API 调用,不会产生问题内容进入日志。
注:基于正则的过滤是第一道防线,而非完整解决方案。对抗性用户可以轻易改写 prompt 来绕过模式匹配(如把 “ignore previous instructions” 换成 “disregard prior directives”)。生产系统建议使用专门的 guardrail 模型,如 Llama Guard 或 Azure AI Content Safety。
示例三:Rate Limiting Middleware
LLM API 调用是昂贵的。没有限流,一个恶意用户就能耗尽你的预算。以下是一个简单的限流 middleware:
const { BaseMiddleware } = require('./middleware');
class RateLimitMiddleware extends BaseMiddleware {
constructor(maxCallsPerMinute = 60) {
super();
this.maxCalls = maxCallsPerMinute;
// 注:生产环境请使用 Redis 等实现分布式状态
// 内存状态在多容器或 serverless 环境下无法工作
this.callTimes = [];
}
async *processRequest(context) {
const now = Date.now();
// 移除 60 秒窗口外的记录
this.callTimes = this.callTimes.filter(t => now - t < 60000);
// 达到限制时,等待最旧记录过期
if (this.callTimes.length >= this.maxCalls) {
const oldestCall = this.callTimes[0];
const waitTime = 60000 - (now - oldestCall);
if (waitTime > 0) {
await new Promise(resolve => setTimeout(resolve, waitTime));
}
}
this.callTimes.push(Date.now());
yield context;
}
async *processResponse(context, result) {
yield result;
}
async *processError(context, error) {
throw error;
}
}使用:
const agent = new Agent({
middleware: [new RateLimitMiddleware({ maxCallsPerMinute: 30 })]
});现在你的 agent 不会被滥用而发起无限 API 调用了。Middleware 会自动将请求节流在预算范围内。
示例四:PII Redaction Middleware
考虑一个处理敏感数据的客服 agent 场景。PII redaction middleware 可以检测并清洗输入和输出中的个人信息:
const { BaseMiddleware } = require('./middleware');
class PIIRedactionMiddleware extends BaseMiddleware {
constructor() {
super();
this.patterns = [
{ regex: /\b\d{3}-\d{2}-\d{4}\b/g, replacement: '[SSN-已去敏]' },
{ regex: /\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}\b/g, replacement: '[邮箱-已去敏]' },
{ regex: /\b\d{3}[-.]?\d{3}[-.]?\d{4}\b/g, replacement: '[电话-已去敏]' },
{ regex: /\b\d{4}[\s-]?\d{4}[\s-]?\d{4}[\s-]?\d{4}\b/g, replacement: '[银行卡-已去敏]' },
];
}
_redact(text) {
for (const { regex, replacement } of this.patterns) {
text = text.replace(regex, replacement);
}
return text;
}
async *processRequest(context) {
// 在输入到达模型之前去敏
if (context.operation === 'model_call' && Array.isArray(context.data)) {
for (const msg of context.data) {
if (msg.content) {
msg.content = this._redact(msg.content);
}
}
}
yield context;
}
async *processResponse(context, result) {
// 在输出到达用户之前去敏
if (result?.message?.content) {
result.message.content = this._redact(result.message.content);
}
yield result;
}
async *processError(context, error) {
throw error;
}
}现在敏感数据永远不会暴露在系统之外:
输入: "客户来电 555-123-4567,邮箱 john@example.com"
输出: "客户来电 [电话-已去敏],邮箱 [邮箱-已去敏]"注:对于流式响应,PII 去敏需要缓冲 chunks 直到有足够上下文检测模式。
Agent 如何使用 Middleware
Agent 内部将其核心操作路由经过 middleware 链:
class Agent {
constructor(config) {
this.middlewareChain = new MiddlewareChain(config.middleware || []);
this.name = config.name;
}
async run(task) {
// ... 准备消息 ...
// Model 调用包裹 middleware
const completionResult = await this.middlewareChain.execute(
'model_call',
{
agentName: this.name,
agentContext: this.context,
data: llmMessages,
},
async (ctx) => {
return await this.modelClient.create(ctx.data, { tools: this.tools });
}
);
// Tool 执行包裹 middleware
for (const toolCall of completionResult.toolCalls) {
const toolResult = await this.middlewareChain.execute(
'tool_call',
{
agentName: this.name,
agentContext: this.context,
data: toolCall,
},
async (ctx) => {
return await this._executeTool(ctx.data);
}
);
}
}
}middlewareChain.execute() 方法依次调用每个 middleware。每个 middleware 收到操作详情后,可以决定是继续执行、修改数据,还是直接阻止。
MiddlewareChain 执行器
实际实现中,你需要一个小型的执行器来运行 middleware 链:
class MiddlewareChain {
constructor(middlewares) {
this.middlewares = middlewares;
}
async execute(operation, context, func) {
// 构建处理管道
let index = 0;
const next = async () => {
if (index >= this.middlewares.length) {
return await func(context);
}
const middleware = this.middlewares[index++];
const gen = middleware.processRequest(context);
let result = await gen.next();
if (result.done) {
return result.value;
}
// 继续到下一个 middleware
return await next();
};
try {
// 执行请求链
const result = await func(context);
// 逆序执行响应链(post-processing)
for (let i = this.middlewares.length - 1; i >= 0; i--) {
const gen = this.middlewares[i].processResponse(
{ ...context, data: result },
result
);
await gen.next();
}
return result;
} catch (error) {
// 错误处理链
for (let i = this.middlewares.length - 1; i >= 0; i--) {
const gen = this.middlewares[i].processError(context, error);
const result = await gen.next();
if (!result.done) {
throw error; // 重新抛出未处理的错误
}
}
throw error;
}
}
}组合多个 Middleware
Middleware 可以自然地组合。顺序很重要——按你提供的顺序执行:
const agent = new Agent({
middleware: [
new LoggingMiddleware(),
new GuardrailMiddleware(),
new RateLimitMiddleware({ maxCallsPerMinute: 30 }),
new PIIRedactionMiddleware(),
]
});请求流向:Logging → Guardrail → Rate Limit → (执行) → PII Redaction → Logging
如果 Guardrail middleware 阻止了请求,后续的限流和执行都不会发生。这种短路行为是刻意的——被阻止的操作不应浪费资源。
同一模式,不同框架
Middleware 模式并非 PicoAgents 独有——这正是生产级 agent 框架处理控制和可观测性的方式。语法不同,但核心架构一致:拦截操作、可选地修改或阻止、然后继续。
Microsoft Agent Framework 提供了三种 middleware 接口:
Middleware(包裹 agent runs)ToolMiddleware(包裹 tool 调用)LmMiddleware(包裹 LLM 请求)
可以用类、函数或装饰器定义:
const { AgentMiddleware, AgentRunContext } = require('agent-framework');
class SecurityMiddleware extends AgentMiddleware {
async process(context, next) {
if (isMalicious(context.messages)) {
context.result = new AgentRunResponse({ messages: [...] });
context.terminate = true; // 停止执行
return;
}
await next(context);
}
}原文链接:Agent Middleware: Adding Control and Observability to AI Agents
翻译 — Feb 15, 2025

Made with ❤ and at Guangzhou.
