使用 LangChain 和 Node.js 提取数据

前言
鉴于大家对 《TypeChat 入门指南》这篇文章的热烈讨论和对 AI 技术的热情,很多朋友私信写到也想更多了解 LangChain 这个框架
所以在这篇文章中,我将分享如何使用 LangChain(一个用于构建 AI 驱动应用程序的框架)通过 GPT 和 Node.js 提取和生成结构化 JSON 数据。 我将分享代码片段和相关的说明来帮助你设置和运行该项目
关于 LangChain
LangChain 是一个具有创新性且集成了许多功能的框架,旨在简化 「AI 驱动应用程序」的开发
凭借其模块化架构,它提供了一套十分全面的组件,用于制作 promt 模板、连接到不同的数据源以及与各种工具无缝交互
通过简化 promt 工程、数据源集成和工具交互,LangChain 使开发者能够专注于应用核心逻辑,提升开发效率
LangChain 支持 Python 和 JavaScript API,具有很高的适配性,使开发人员能够跨多个平台和使用场景利用自然语言处理和人工智能的力量
LangChain 包含从 LLM 中获取结构化(如 JSON 格式)输出的工具。 让我们利用 LangChain的工具来发挥我们的优势
安装和设置
我假设你现在是使用 NodeJS 的最新版本之一。 我使用的是 Node.js v18。如果需要更多详细信息,请访问 LangChain 网站
首先创建一个 Node.js 项目
- 创建一个新的目录,并进入目录
- 运行 npm 初始化命令来创建 Node.js 项目
- 创建一个
index.js文件
然后,让我们安装 LangChain 与 dotenv ,并配置 API 密钥
$ npm i langchain
$ npm i dotenv -D让我们在 JS 文件顶部导入所需的依赖项
import dotenv from 'dotenv'
import { z } from "zod";
import { OpenAI } from "langchain/llms/openai";
import { PromptTemplate } from "langchain/prompts";
import {
StructuredOutputParser,
OutputFixingParser,
} from "langchain/output_parsers";
dotenv.config()生成数据
让我们从生成一些假数据开始,看看解析的可能性
定义输出 Schema
首先,需要告诉框架我们想要得到什么。 LangChain 支持使用名为 Zod 的库来定义预期的 Schema:
const parser = StructuredOutputParser.fromZodSchema(
z.object({
name: z.string().describe("人类的名字"),
surname: z.string().describe("人类的姓氏"),
age: z.number().describe("人类的年龄"),
appearance: z.string().describe("人类的外形描述"),
shortBio: z.string().describe("简介"),
university: z.string().optional().describe("就读大学的名称"),
gender: z.string().describe("人类的性别"),
interests: z
.array(z.string())
.describe("关于人类兴趣的 json 数组"),
})
);Prompt 模版
为了使用这个模板,我们需要创建一个名为 PromptTemplate 的 LangChain 结构。 它将包含来自解析器的格式指令
const formatInstructions = parser.getFormatInstructions();
const prompt = new PromptTemplate({
template:
`生成虚拟人物的详细信息.\n{format_instructions}
人物描述: {description}`,
inputVariables: ["description"],
partialVariables: { format_instructions: formatInstructions },
});尝试运行
要执行结构化输出,请使用以下的输入来调用 OpenAI 模型:
const model = new OpenAI({
openAIApiKey: process.env.OPENAI_API_KEY,
temperature: 0.5,
model: "gpt-3.5-turbo"
});
const input = await prompt.format({
description: "一个男人,生活在英国",
});
const response = await model.call(input);
console.log('生成的结果:', response)以下是将发送到 AI 模型的内容。 这很可能会在未来的 LangChain 版本中发生改变
生成虚拟人物的详细信息.
You must format your output as a JSON value that adheres to a given "JSON Schema" instance.
"JSON Schema" is a declarative language that allows you to annotate and validate JSON documents.
For example, the example "JSON Schema" instance {{"properties": {{"foo": {{"description": "a list of test words", "type": "array", "items": {{"type": "string"}}}}}}, "required": ["foo"]}}}}
would match an object with one required property, "foo". The "type" property specifies "foo" must be an "array", and the "description" property semantically describes it as "a list of test words". The items within "foo" must be strings.
Thus, the object {{"foo": ["bar", "baz"]}} is a well-formatted instance of this example "JSON Schema". The object {{"properties": {{"foo": ["bar", "baz"]}}}} is not well-formatted.
Your output will be parsed and type-checked according to the provided schema instance, so make sure all fields in your output match exactly!
Here is the JSON Schema instance your output must adhere to:
'''json
{"type":"object",
"properties":
{
"name":{"type":"string","description":"人类的名字"},
"surname":{"type":"string","description":"人类的姓氏"},
"age":{"type":"number","description":"人类的年龄"},
"appearance":{"type":"string", "description":"人类的外形描述"},
"shortBio":{"type":"string","description":"简介"},
"university":{"type":"string","description":"就读大学的名称"},
"gender":{"type":"string","description":"人类的性别"},
"interests":{"type":"array","items":{"type":"string"},"description":"关于人类兴趣的 json 数组"}
},
"required":
["name","surname","age","appearance","shortBio","gender","interests"],
"additionalProperties":false,"$schema":"<http://json-schema.org/draft-07/schema#>"}
'''
Person description: 一个男人,生活在英国.输出的模型大概是这样的
{
"name": "John",
"surname": "Smith",
"age": 25,
"appearance": "John is a tall, slim man with brown hair and blue eyes.",
"shortBio": "John is a 25-year-old man from the UK. He is currently studying at Cambridge University and enjoys travelling and collecting antiques.",
"university": "Cambridge University",
"gender": "Male",
"interests": ["Travelling", "Collecting antiques"]
}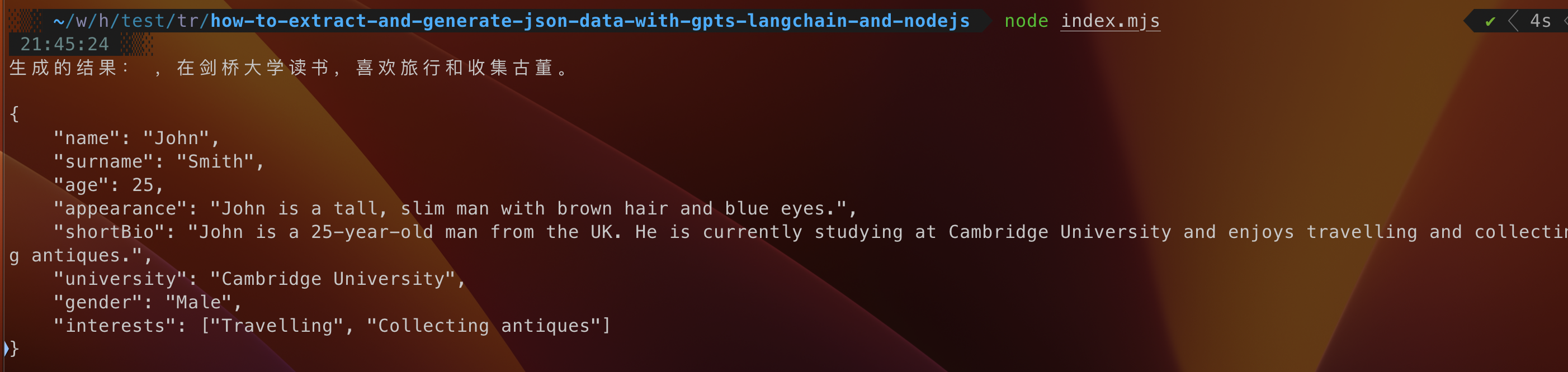
正如你所看到的,我们得到了我们所需要的数据。 我们可以生成具有与人物角色其他部分相匹配的复杂描述的完整身份。 如果我们需要丰富我们的模拟数据,我们可以使用另一个 AI 模型根据外观生成照片
错误处理
你可能想知道在生产环境的应用程序中使用 LLM 是否安全。幸运的是,LangChain 就专注于解决这样的问题。 如果输出需要修复,请使用 OutputFishingParser。如果 LLM 输出的内容不符合要求,它会尝试修复错误。
try {
console.log(await parser.parse(response));
} catch (e) {
console.error("解析失败,错误是: ", e);
const fixParser = OutputFixingParser.fromLLM(
new OpenAI({
temperature: 0,
model: "gpt-3.5-turbo",
openAIApiKey: process.env.OPENAI_API_KEY,
}),
parser
);
const output = await fixParser.parse(response);
console.log("修复后的输出是: ", output);
}从文件中提取数据
要使用 LangChain 从文件中加载和提取数据,你可以按照以下步骤操作。 在此示例中,我们将加载 PDF 文件。 方便的是,LangChain 有专门用于此目的的工具。 我们还需要一个额外的依赖。
npm install pdf-parse我们将加载伊隆·马斯克的简介并提取我们之前生成的信息,相关 PDF 文件已经放在 github 仓库
首先让我们创建一个新文件,例如 Structured-pdf.js。 让我们从加载 PDF 开始
import { PDFLoader } from "langchain/document_loaders/fs/pdf";
const loader = new PDFLoader("./elon.pdf");
const docs = await loader.load();
console.log(docs);我们需要修改 prompt 模板以指示这是一个提取操作,而不是生成操作。 还必须修改 prompt 来修复 JSON 渲染问题,因为结果有时会不一致
const prompt = new PromptTemplate({
template:
"Extract information from the person description.\n{format_instructions}\nThe response should be presented in a markdown JSON codeblock.\nPerson description: {inputText}",
inputVariables: ["inputText"],
partialVariables: { format_instructions: formatInstructions },
});最后,我们需要扩展允许的输出长度(比生成的情况多一点数据),因为默认值为 256 个 token。 我们还需要使用加载的文档而不是预定的人员描述来调用模型。
const model = new OpenAI({
openAIApiKey: process.env.OPENAI_API_KEY,
temperature: 0.5,
model: "gpt-3.5-turbo"
});由于这些修改,我们得到以下输出:
{
name: 'Elon',
surname: 'Musk',
age: 51,
appearance: 'normal build, short-cropped hair, and a trimmed beard',
// truncated by me
shortBio: "Elon Musk, a 51-year-old male entrepreneur, inventor, and CEO, is best known for his...',
gender: 'male',
interests: [
'space exploration',
'electric vehicles',
'artificial intelligence',
'sustainable energy',
'tunnel construction',
'neural interfaces',
'Mars colonization',
'hyperloop transportation'
]
}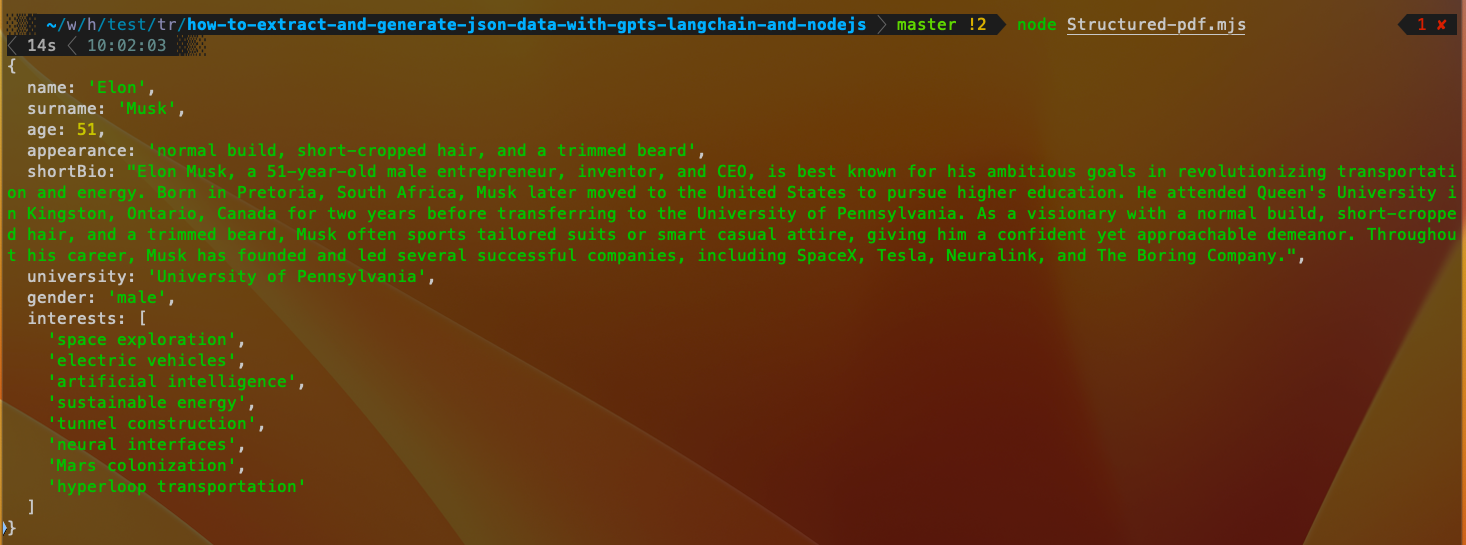
通过执行这些步骤,我们已经从 PDF 文件中提取了结构化 JSON 数据! 这种方法用途广泛,可以根据特定用例进行调整
结论
总之,通过利用 LangChain、GPT 和 Node.js,你可以创建强大的应用程序,用于从各种来源提取和生成结构化 JSON 数据
潜在的应用程序市场是巨大的,只要有一点创造力,你就可以使用这项技术来构建新的应用程序和解决方案
你可以在这个 仓库 中找到本篇文章的所有代码
翻译 — Sep 12, 2023

Made with ❤ and at Guangzhou.
